
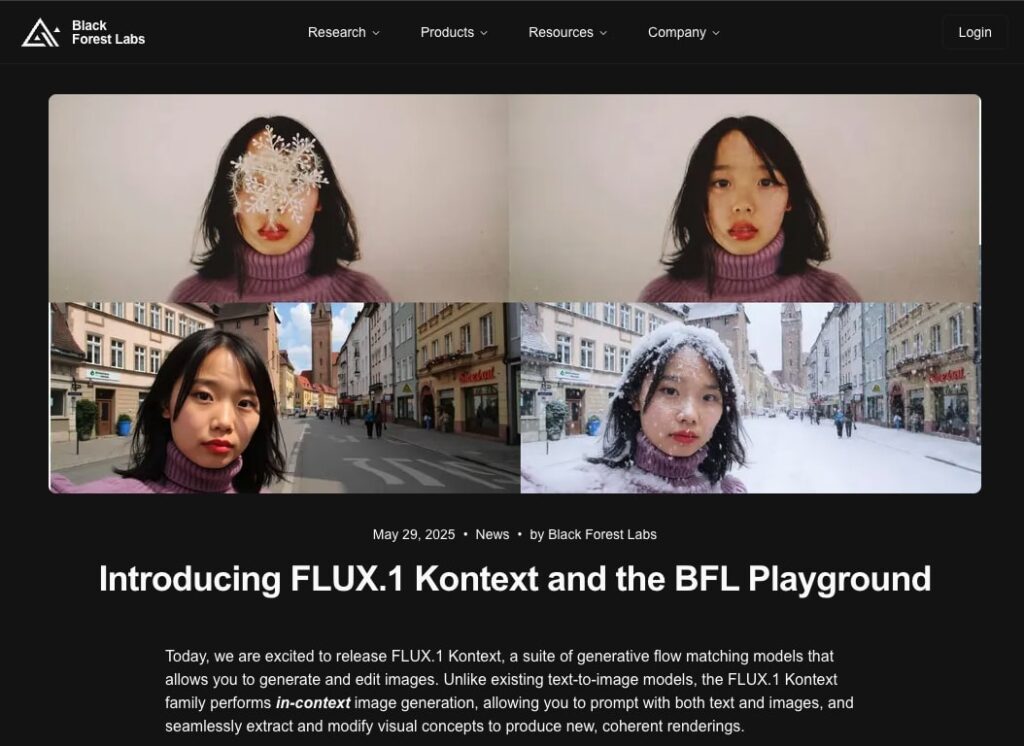
マルチモーダル画像生成AI
画像生成AIの「Stability.AI」の技術者が独立し「Black Forest Lab」を立ち上げてFLUXを発表してから10ヶ月。
新しく「FLUX.1 Kontext」がリリースされました。
特徴はマルチモーダルで参考画像とテキスト(プロンプト)から画像を作成できます。
FLUX Playground
Flux.1 Kontextのモデルは、「dev」、「Pro」、「max」と3種類が提供されます。
Proモデルについては、こちらで無料で試すことができます。
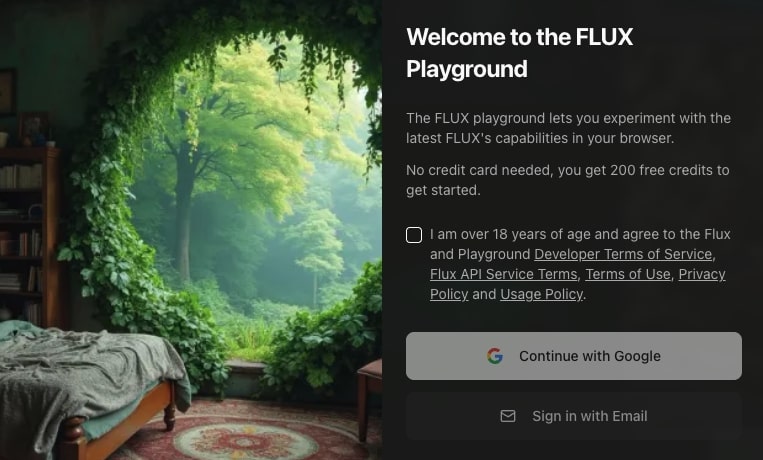
Playgroundにアクセスするとサインインを求められます。今回はGoogleアカウントでサインインします。
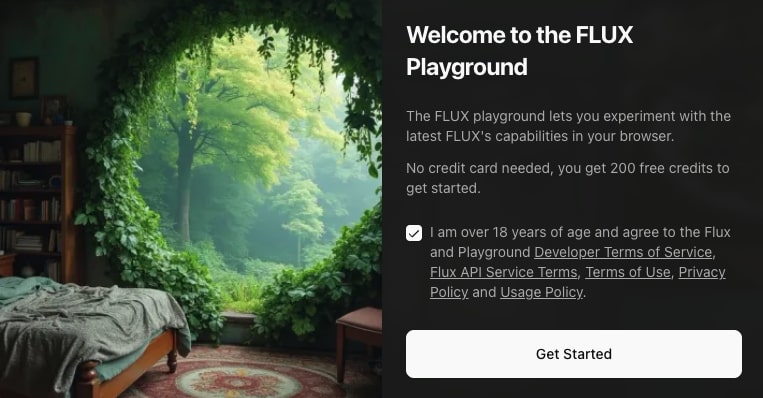
サインイン後、規約への同意が求められますのでチェックをONにし「Get Started」ボタンをクリックします。
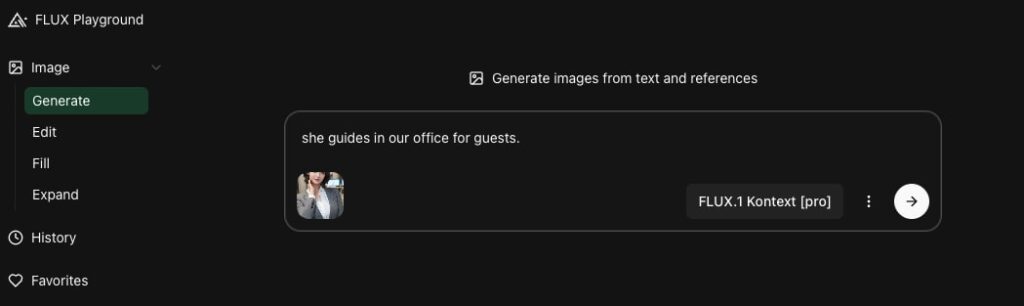
以下のような入力ボックスに「参考画像」とプロンプトを入力します。こちらが今回使用した参考画像です。

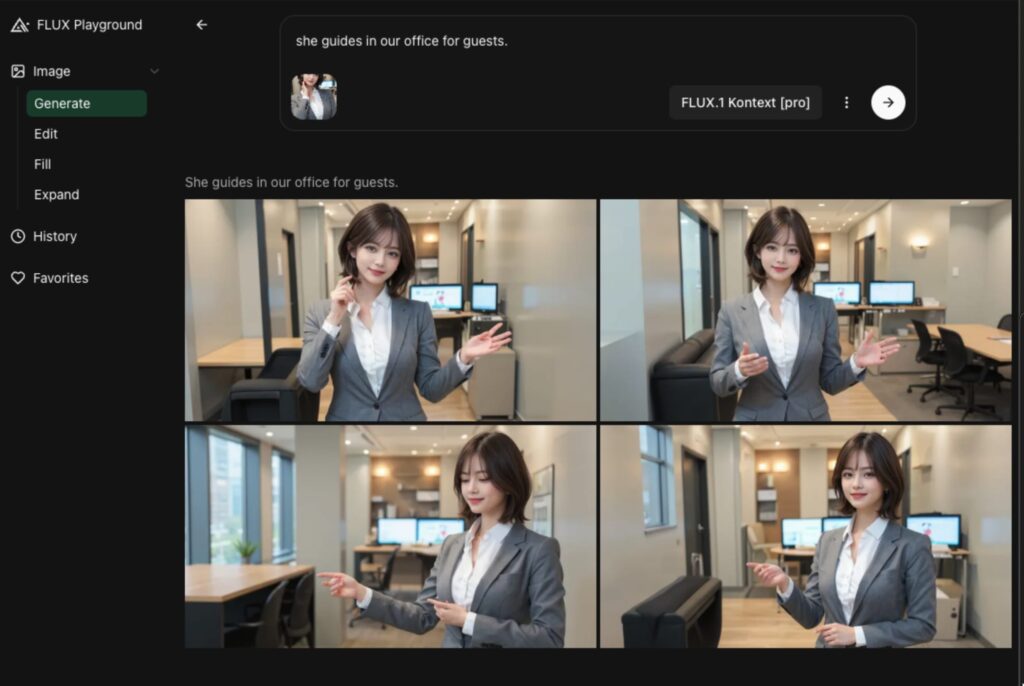
プロンプトには、「彼女はオフィスでゲストを案内している」と入力し、作成ボタンをクリックします。作成ボタンの橫の3点をクリックするとサイズ、枚数の指定ができます。
以下の4枚の画像が作成されました。
参考画像の女性がポーズと表情(ちょっとだけ)を変っています。
続けて「作成」ボタンをクリックすると更に4枚の画像が作成されました。サイズなどは指定していませんが、縦長のサイズになりました。

その後、サイズ指定を行いますが上手く効きません。
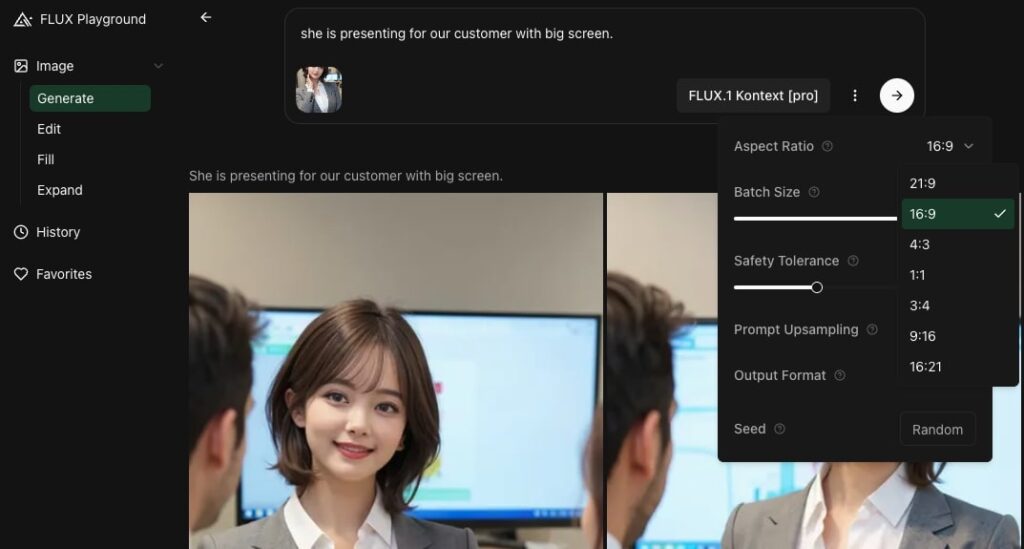
別んが画像を使用すると最初だけはサイズ指定が効きますが、次は効かないようです。
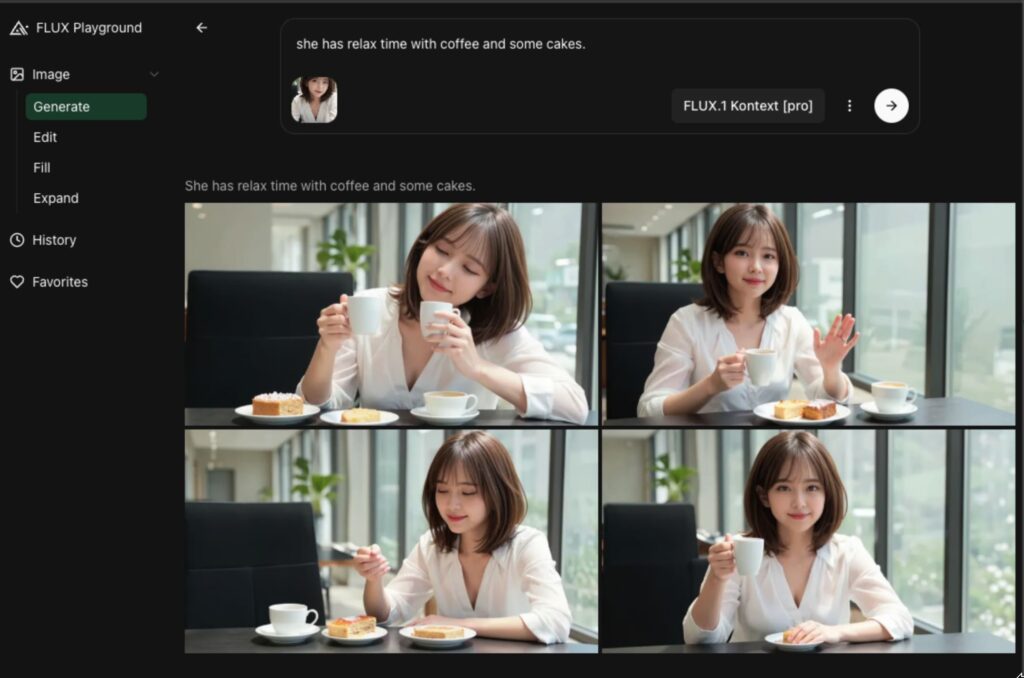
こちらは、かなり表情が変わっていますが、コーヒーカップがいくつあれば満足なのでしょうか?
画像生成AIにありがちな指の変形はないようです。
まとめ
サインインすると1日に200クレジットが付与されます。1画像4クレジット消費しますので1日50枚は作成できそうです。
SeaArt.AIなどで作成した画像からポーズ・表情のバリエーションを作成するのには非常に便利です。

コメント