
詳細設定
SeaArt.AIの画像作成画面の右ペイン下側にある「Advanced Config」について解説します。アカウントの設定で言語を日本語にすれば日本語でも説明がポップアップします。
以下に、各項目を分かりやすく解説します。イメージしやすいように例えを交えています 🌟
1. Embedding(エンベッディング)
「言葉をAIが理解できる数字に翻訳する技術」
例えば「猫」という単語を、[0.2, -1.5, 3.0…] のような数字のリストに変換します。
この数字は「毛の長さ」「耳の形」などの特徴を表現しており、AIが画像生成のヒントとして使います。
前回のネガティブ・プロンプトでもお伝えしたように、ある共通した観念(低品質、ネコなど)を学習させたものでトリガーワードと共に使います。
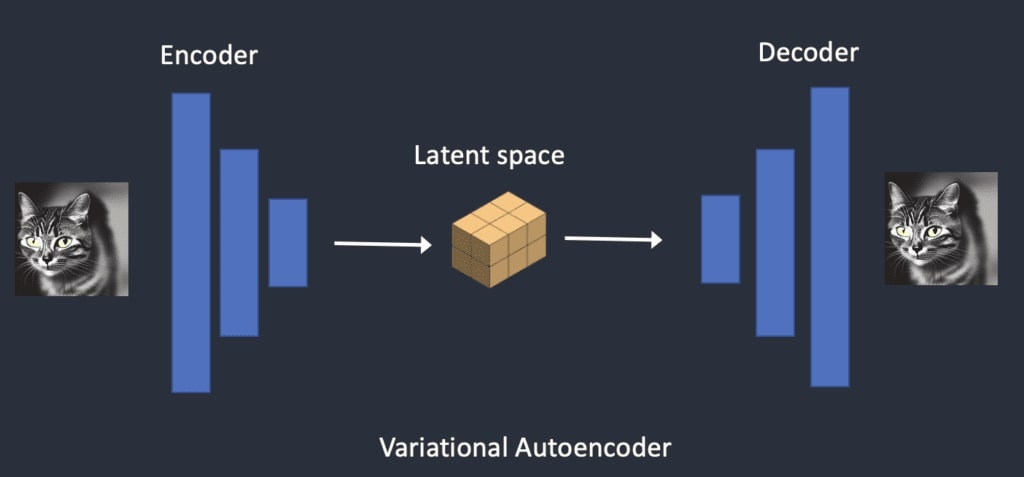
2. VAE(Variational Autoencoder/変分オートエンコーダ)
「画像を圧縮・復元するAIの仕組み」
- エンコーダ:画像を「小さな暗号(潜在空間)」に圧縮(例:1000×1000ピクセル → 64×64の暗号)。
- デコーダ:暗号を元の画像に戻します。
生成プロセスを軽量化するために使われます。
使用するVAEにより圧縮・復元のでデータが省かれたり、追加されたりにより鮮やかさ、鮮明度、塗り具合などが変わります。。
チェックポイント専用のVAEもあれば、汎用のVAEもあります。
How does Stable Diffusion work?
3. LCM(Latent Consistency Model)
「高速生成のための裏ワザ」
通常の生成では100ステップかかる作業を、4~8ステップで終わらせます。
「途中のステップを飛ばしても結果が変わらないように調整する技術」で、速度と品質を両立させます。
SeaArtでONにすると、以下のサンプリングステップ、CFG Scaleが小さい値に変わります。
4. Sampling Method(サンプリング法)
「ノイズ削除の戦略」
ノイズだらけの画像を整える方法です。
- Euler:シンプルで速いが大雑把。
- DDIM:正確だが時間がかかる。
- DPM++:バランス型。
「地図アプリのルート選択」のように、速度と精度のトレードオフがあります。
画像生成AI(拡散モデル)の学習と画像生成
画像生成AIの学習は、与えられた画像にノイズを乗せ、最終的にノイズだらけのデータから、ノイズを除去して元の画像を再現する方法で行われます。
元画像にノイズを乗せていきます。
How does Stable Diffusion work?
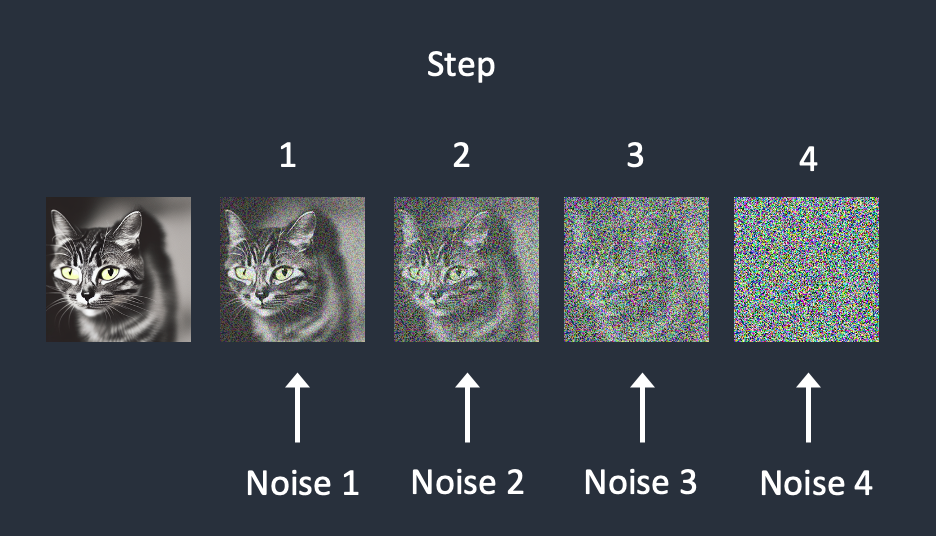
ノイズを除去します。
入力したプロンプト、Embeddingなどからノイズが作成され、ノイズ除去を行い画像を生成します。そのノイズ除去のアルゴリズム(やり方)をSampling Methodと呼びます。
How does Stable Diffusion work?
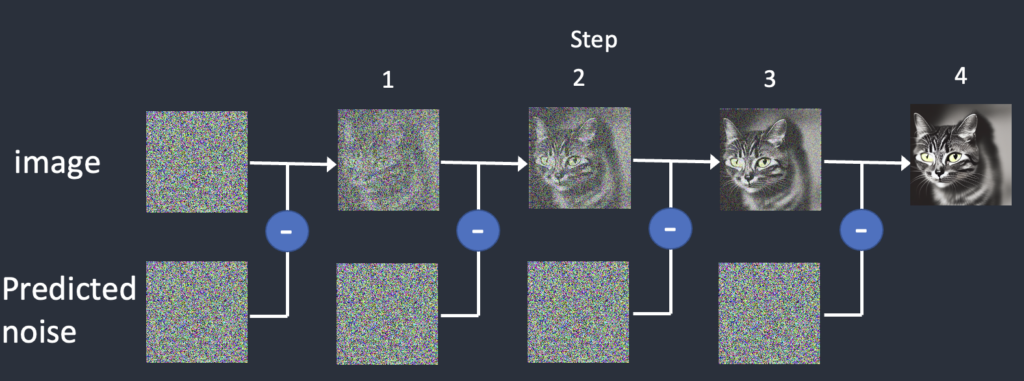
5. Sampling Steps(サンプリングステップ数)
「AIの描き直し回数」
ステップ数が多いほど、ノイズを細かく修正します(例:15ステップ=ラフスケッチ、50ステップ=精密画)。
ただし、時間と計算量が増加します。
ノイズを加える、ノイズを除去する毎回の作業を1ステップといいます。
学習の際には、学習モデルにもよりますが1000ステップほどノイズを乗せていきます。画像を生成する際には逆を行うので1000ステップを行う必要があります。
しかし、1000ステップのノイズ除去を行うと膨大な時間がかかります。そのため、1000ステップを大きく分け、デフォルトのサンプルステップ数20であれば20ステップに出来るように間をスキップします。
以下の画像はサンプルステップ数20で作成しています。

6. CFG Scale(Classifier-Free Guidance Scale)
「プロンプトの厳密さ」
CFG Scale(Classifier Free Guidance scale)は、プロンプトにどれくらい従うかの指標です。
最低は「1」最大「30」デフォルト「7」です。数字を大きくするほどプロンプトに従うようになりますが、大きすぎると画としては破綻します。
逆に小さくすると、Stable Diffusionの自由度が上がり独創的になります。
- 低い値(1~5):AIが自由に創作(例:「犬」→ 空を飛ぶ犬)。
- 高い値(10~15):プロンプトに忠実(例:「犬」→ リアルな犬の写真)。
「指示の厳しさを決めるパラメータ」 と考えると分かりやすいです。
7. Seed(シード値)
「ランダム生成のための秘密の数値」
プロンプトは解釈されて最終的に数字に変換されます。その数字をどれだけ変化させるかを決める値です。
そのため、同じプロンプトで同じシード値を使うと、全く同じ画像が再現されます。
「ランダムネスの種(タネ)」を固定することで再現性を保ちます。
「-1(マイナス1)」を指定すると毎回ランダムな値を使用します。
8. Clip Skip
「プロンプト解釈の深さを調整する機能」
CLIPモデル(テキストを理解するAI)の層を途中で止めることで、解釈を変えます。
- Clip Skip=1:深く解釈(抽象的な意味を重視)。
- Clip Skip=2:浅く解釈(文字通りの意味を重視)。
「詩を深読みするか、字面だけ読むか」の違いのようなものです。
全体のイメージ
「AIが『暗号化された画像(VAE)』を『言葉の指示(Embedding)』に沿って、ステップを重ね(Sampling Steps)、戦略的に(Sampling Method)ノイズを消し、時には高速化(LCM)しながら、プロンプトの厳密さ(CFG Scale)を調整して画像を生成する」 という流れです。シード値はその過程の「偶然性」をコントロールします🎨


コメント